How It Works
System at a Glance
From document ingestion to semantic filtering and RAG-powered analysis.
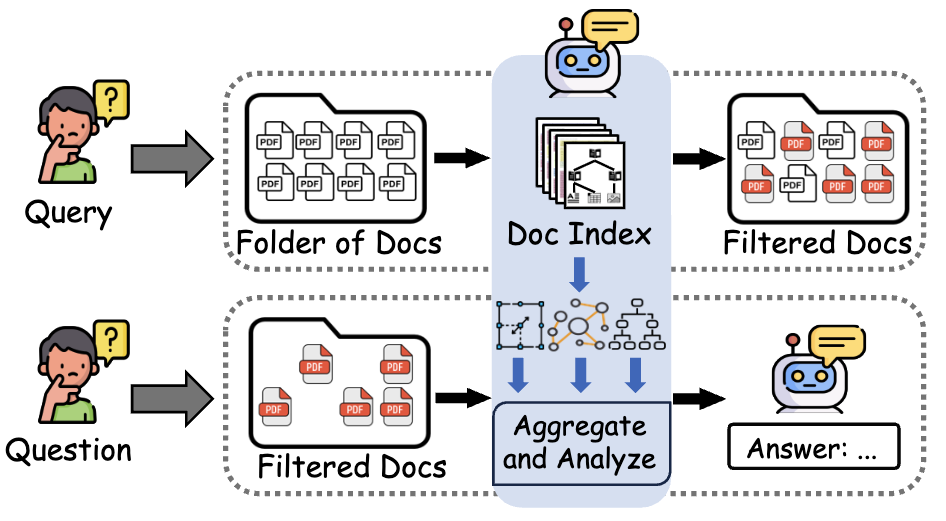
Workflow Pipeline
End-to-end flow from PDF upload through parsing, indexing, filtering, to RAG Q&A output.
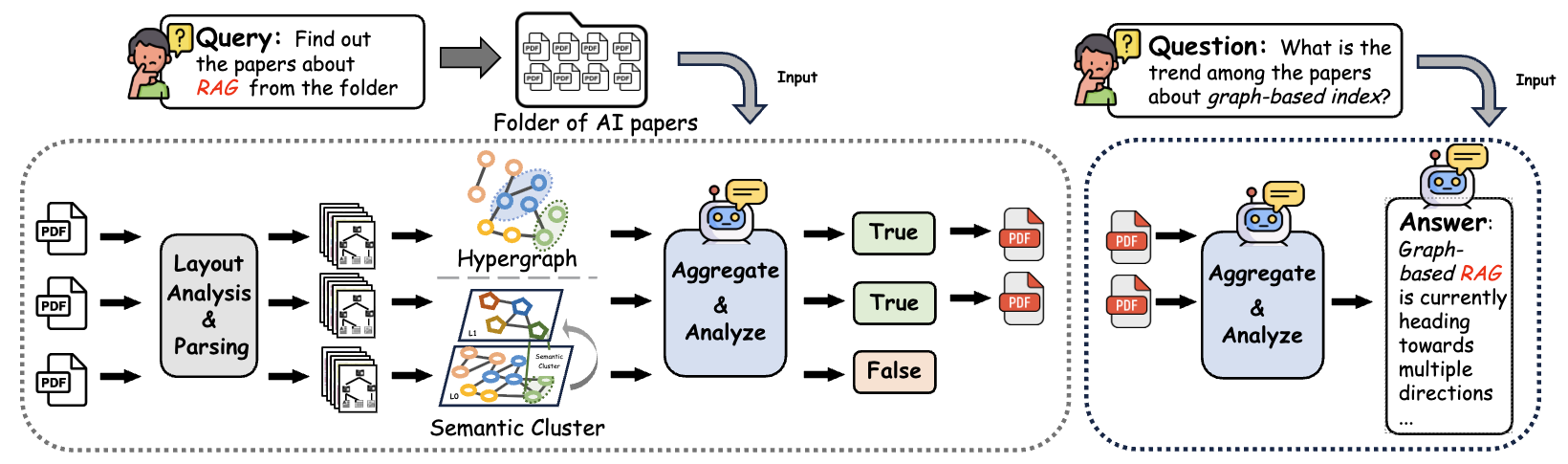
Index Construction
Document tree building, PC-KMeans clustering, and hyperedge extraction pipeline.
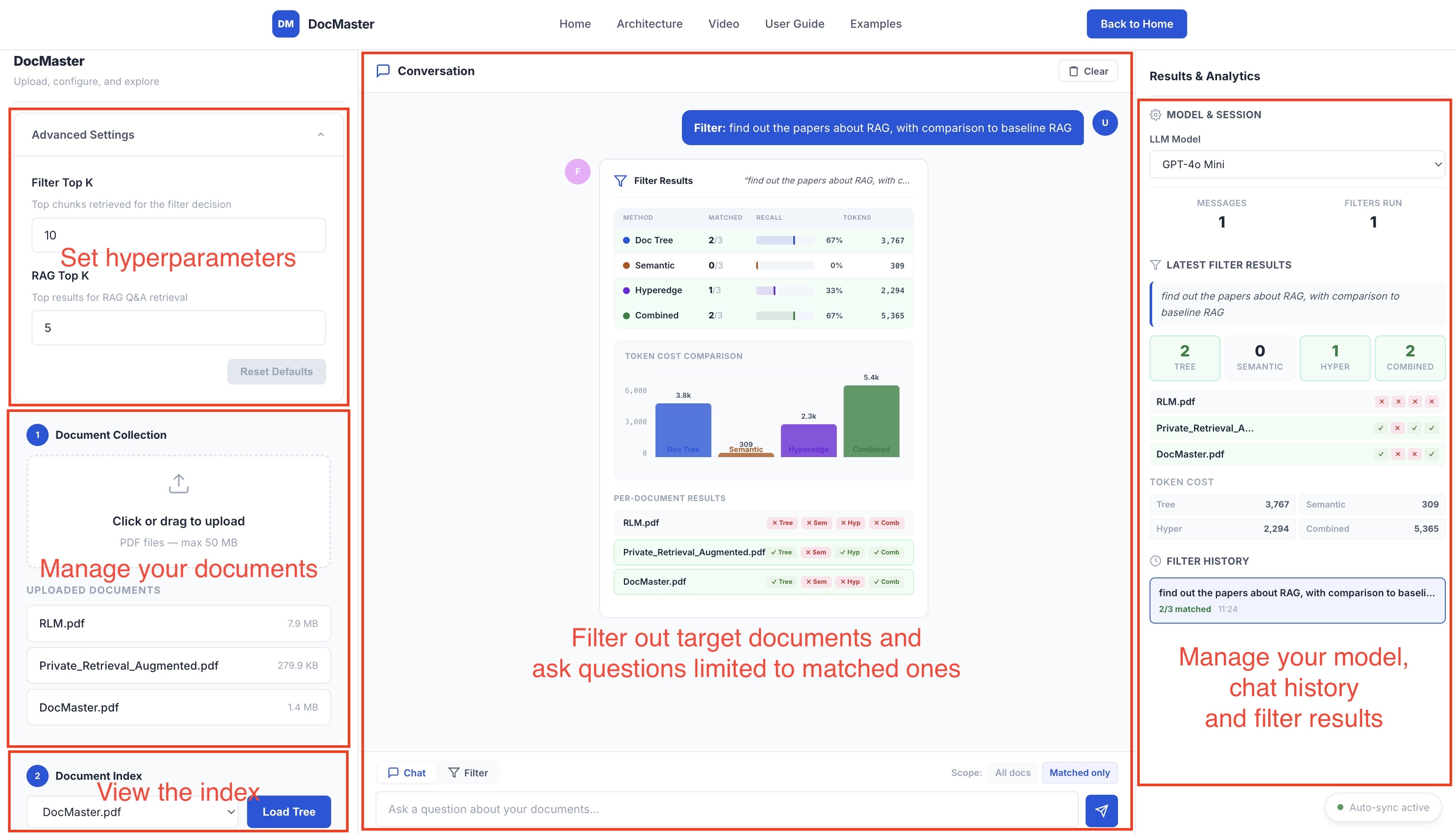
Demo System Layout
Two-column interface with document management on the left and filtering/chat on the right.